
Overview
This project implements a complete Retrieval-Augmented Generation (RAG) workflow for story-based question answering
and benchmarks how chunking strategy impacts answer quality. The pipeline uses a NarrativeQA-style setup on a real story
(Project Gutenberg #2347) and evaluates answers using ROUGE-L and BLEU, along with a combined average score
Avg = (ROUGE-L + BLEU) / 2.
Recruiter-level takeaway: this demonstrates that I can (1) build a working RAG system end-to-end, and (2) run controlled experiments to justify engineering decisions instead of guessing.
Problem Statement
Story question answering is challenging because correct answers depend on specific evidence distributed across the text. A RAG system can help by retrieving relevant passages, but the output quality depends heavily on decisions like:
- How the text is split into chunks (fixed vs sentence-aware)
- How much overlap is used (too little fragments evidence; too much adds redundancy)
- How many chunks are provided to the generator (TOP_K)
The goal was to design a pipeline that is reproducible and then measure the effect of these choices objectively.
Dataset
- Story source: Project Gutenberg #2347 (used as the narrative context)
- Task style: NarrativeQA-like question answering (answer using retrieved story context)
System Architecture (End-to-End RAG)
The pipeline covers the full RAG loop: preprocessing → chunking → embedding/indexing → retrieval → reranking → generation → evaluation.
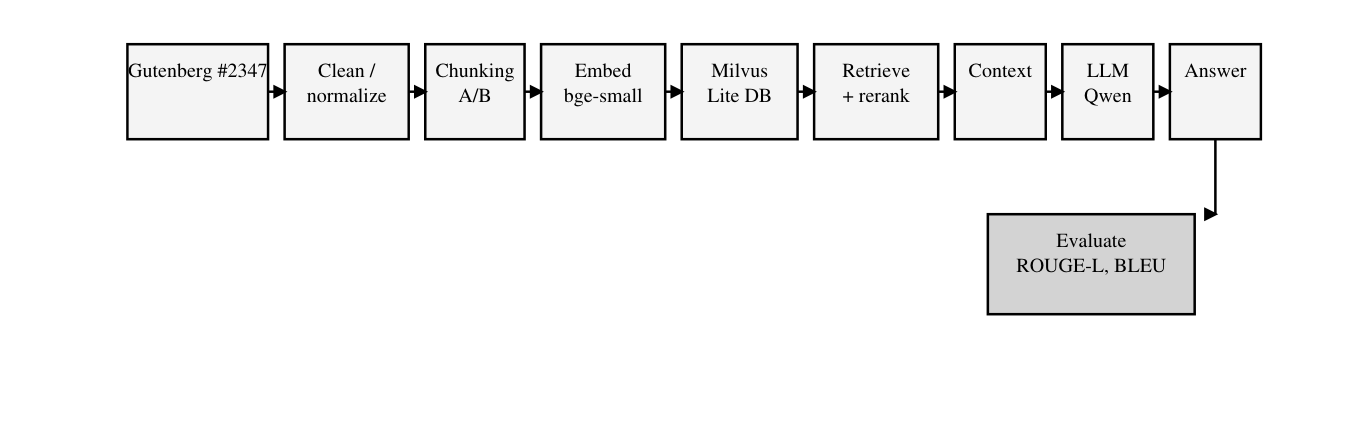
Core components
- Vector DB: Milvus Lite
- Embedding model:
BAAI/bge-small-en-v1.5 - Reranker:
BAAI/bge-reranker-v2-m3 - Retriever approach: retrieve a larger pool (RETRIEVE_K) → rerank → select TOP_K for prompt context
- Generator LLM: Qwen family (0.5B and 1.5B variants tested in the report)
Chunking Strategies (What Was Compared)
Chunker A — Fixed-length chunks (baseline)
- Fixed chunk size (report uses ~1200 characters for controlled comparison)
- Overlap measured in characters (e.g., 200 vs 350)
Chunker B — Sentence-aware / structure-aware chunking
- Attempts to preserve sentence boundaries so evidence isn’t split mid-thought
- Overlap measured in sentences (e.g., 2 vs 4)
- A paragraph-overlap variant was also included in the sweep
Why this matters: better chunk boundaries can improve retrieval relevance and make the generator less likely to hallucinate or miss crucial details.
Experiment Design
I used a controlled setup where most pipeline components are fixed, while the following are swept:
- Overlap settings (chars for A; sentences/paragraph for B)
- TOP_K (how many chunks go into the prompt)
- Generator size (0.5B vs 1.5B)
This makes it possible to attribute differences in ROUGE/BLEU mainly to chunking/overlap/context configuration instead of unrelated changes.
Experiment matrix (E1–E9)
The following tables summarize the results for both chunkers across all experiments.

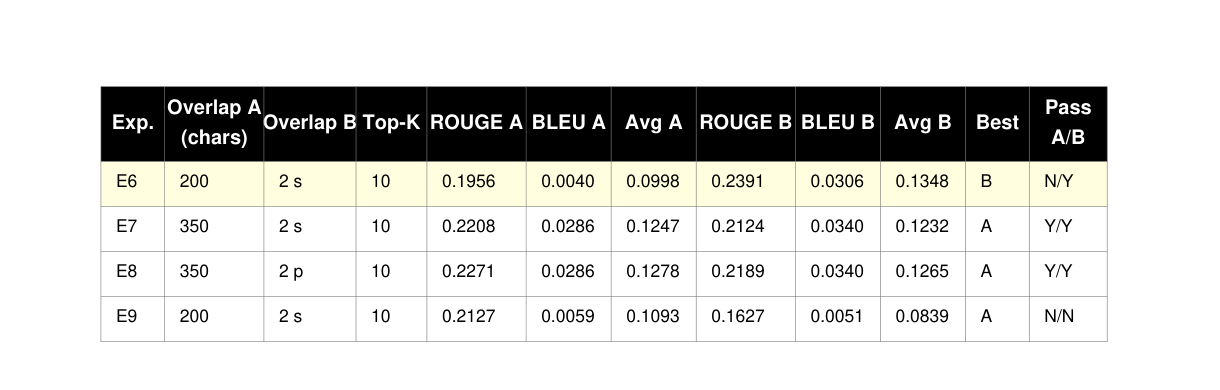
Results
Best-performing configuration
The strongest combined performance is achieved by Experiment E6 with Chunker B, with:
- ROUGE-L = 0.2391
- BLEU = 0.0306
- Avg = 0.1348
Interpretation: sentence-aware chunking produced better evidence coherence and improved overlap-based evaluation metrics under the tested settings.
Average score comparison (A vs B across experiments)
This chart shows the combined average score across experiments for both chunkers:
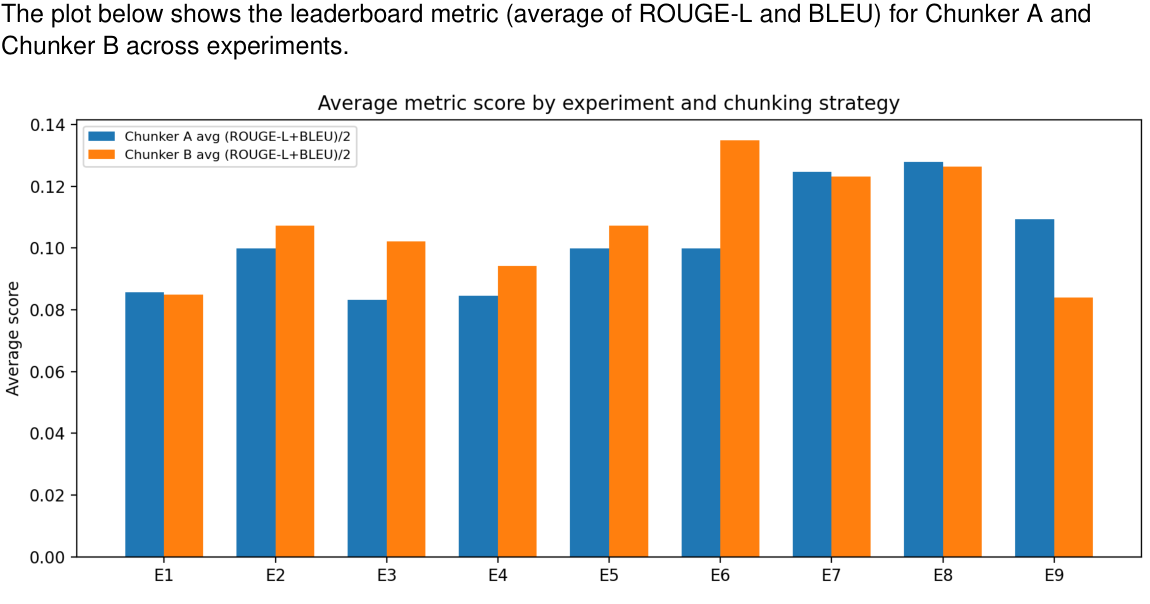
Engineering Takeaways
- Chunking is a primary lever in RAG quality. Sentence-aware chunking can preserve meaning and boost retrieval usefulness.
- Overlap is a trade-off. Too little overlap fragments evidence; too much overlap reduces diversity and can waste context budget.
- Evaluation metrics behave differently. ROUGE-L often correlates with capturing key phrases; BLEU can be harsh on paraphrasing.
- Model size is not the only driver. Retrieval design + prompt/context selection can dominate gains over simply using a larger generator.